

Here's my latest on Medium: Much has been said recently about privilege and, specifically, white male privilege. How it feeds into the success of many people, especially those who benefit from institutions that privilege whiteness, maleness, and more specifically, maleness that falls within the strict bounds of gender and sexuality norms. It has been said… Continue reading Tales of Privilege
Episode 8: A New Beginning
Some of you know that I recently left Red Hat. There are multiple reasons for this, mostly to do with a wonderful opportunity that came my way (more on that later). First, Red Hat. I learned more in my 4 years there than at any other time in my career. I went from being just… Continue reading Episode 8: A New Beginning
El-Deko – Why Containers Are Worth the Hype
Video above from Kubernetes 1.0 Launch event at OSCON
In the above video, I attempted to put Red Hat’s container efforts into a bit of context, especially with respect to our history of Linux platform development. Having now watched the above video (they forced me to watch!) I thought it would be good to expound on what I discussed in the video.
Admit it, you’ve read one of the umpteen millions of articles breathlessly talking about the new Docker/Kubernetes/Flannel/CoreOS/whatever hotness and thought to yourself, Wow, is this stuff overhyped.
There is some truth to that knee-jerk reaction, and the buzzworthiness of all things container-related should give one pause - It’s turt^H^H^H^Hcontainers all the way down!
I myself have often thought how much fun it would be to write the Silicon Valley buzzword-compliant slide deck, with all of the insane things that have passed for “technical content” over the years, from Java to Docker and lots of other nonsense in between. But this blog post is not about how overhyped the container oeuvre is, but rather why it’s getting all the hype and why - and this is going to hurt writing this - it’s actually deserved.
IT, from the beginning, has been about doing more, faster. This edict has run the gamut from mainframes and microcomputers to PCs, tablets, and phones. From timeshare computing to client-server to virtualization and cloud computing, the quest for this most nebulous of holy grails, efficiency, has taken many forms over the years, in some cases fruitful and in others, meh.
More recently, efficiency has taken the form of automation at scale, specifically in the realm of cloud computing and big data technologies. But there has been some difficulty with this transition:
- The preferred base of currency for cloud computing, the venerable virtual machine, has proved to be a tad overweight for this transformation.
- Not all clouds are public clouds. The cloudies want to pretend that everyone wants to move to public cloud infrastructure NowNowNow. They are wrong.
- Existing management frameworks were not built for cloud workloads. It’s extremely difficult to get a holistic view of your infrastructure, from on-premises workloads to cloud-based SaaS applications and deployments on IaaS infrastructure.
While cloud computing has had great momentum for a few years now and shows no signs of stopping, its transformative power over IT remains incomplete. To complete the cloudification of IT, the above problems need to be solved, which involves rewriting the playbook for enterprise workloads to account for on-premises, hybrid and, yes, public cloud workloads. The entire pathway from dev to ops is currently undergoing the most disruption since the transition from mainframe to client-server. We’re a long ways from the days when LAMP was a thing, and software running on bare metal was the only means of deploying applications. Aside from the “L”, the rest of the LAMP stack has been upended with its replacements in the formative stages.
While we may not know precisely what the new stack will be, we can now make some pretty educated guesses:
- Linux (duh): It’s proved remarkably flexible, regardless of what new workload is introduced. Remember when Andy Tanenbaum tried to argue in 1992 that
monolithic kernels
couldn’t possibly provide the modularity required for modern operating systems? - Docker: The preferred container format for packaging applications. I realize this is now called the Open Container Format, but most people will know it as Docker.
- Kubernetes: The preferred orchestration framework. There are others in the mix, but Kubernetes seems to have the inside track, although its use certainly doesn’t preclude Mesos, et al. One can see a need for multiple, although Kube seems to be “core”.
- OpenShift: There’s exactly one open source application management platform for the Docker and Kubernetes universe, and that’s OpenShift. No other full-featured open source PaaS is built on these core building blocks.
In the interest of marketers everywhere, I give you the “LDKO” or “El-deko” stack. You’re welcome.
Why This is a Thing
The drive to efficiency has meant extending the life of existing architecture, while spinning up new components that can work with, rather than against, current infrastructure. After it became apparent to the vast majority of IT pros that applications would need to straddle the on-premises and public cloud worlds, the search was on for the best way to do this.
Everyone has AWS instances; everyone has groups of virtual machines; and everyone has bare metal systems in multiple locations. How do we create applications that can run on the maximum number of platforms, thus giving devops folks the most choices in where and how to deploy infrastructure at scale? And how do we make it easy for developers to package and ship applications to run on said infrastructure?
At Red Hat, we embraced both Docker and Kubernetes early on, because we recognized their ability to deliver value in a number of contexts, regardless of platform. By collaborating with their respective upstream communities, and then rewriting OpenShift to take advantage of them, we were able to create a streamlined process that allowed both dev and ops to focus on their core strengths and deliver value at a higher level than ever before. The ability to build, package, distribute, deploy, and manage applications at scale has been the goal from the beginning, and with these budding technologies, we can now do it more efficiently than ever before.
Atomic: Container Infrastructure for the DevOps Pro
In the interests of utilizing the building blocks above, it was clear that we needed to retool our core platform to be “container-ready,” hence Project Atomic and its associated technologies:
- Atomic Host: The core platform or “host” for containers and container orchestration. We needed a stripped-down version of our Linux distributions to support lightweight container management. You can now use RHEL, CentOS, and Fedora versions of Atomic Host images to provide your container environment. The immutability of Atomic Host and its
atomic update
feature provides a secure environment to run container-based workloads. - Atomic CLI: This enables users to quickly perform administrative functions on Atomic Host, including installing and running containers as well as performing an Atomic Host update.
- Atomic App: Our implementation of the Nulecule application specification, allowing developers to define and package an application and operations to then deploy and manage that application. This gives enterprises the advantage of a seamless, iterative methodology to complete their application development pipeline. Atomic App supports OpenShift, Kubernetes, and Just Plain Docker as orchestration targets
out of the box
with the ability to easily add more.
Putting It All Together
As demonstrated in the graphic below, the emerging stack is very different from your parents’ Linux. It takes best of breed open source technologies and pieces them together into a cloud native fabric worthy of the DevOps
moniker.
El-Deko in All Its Glory
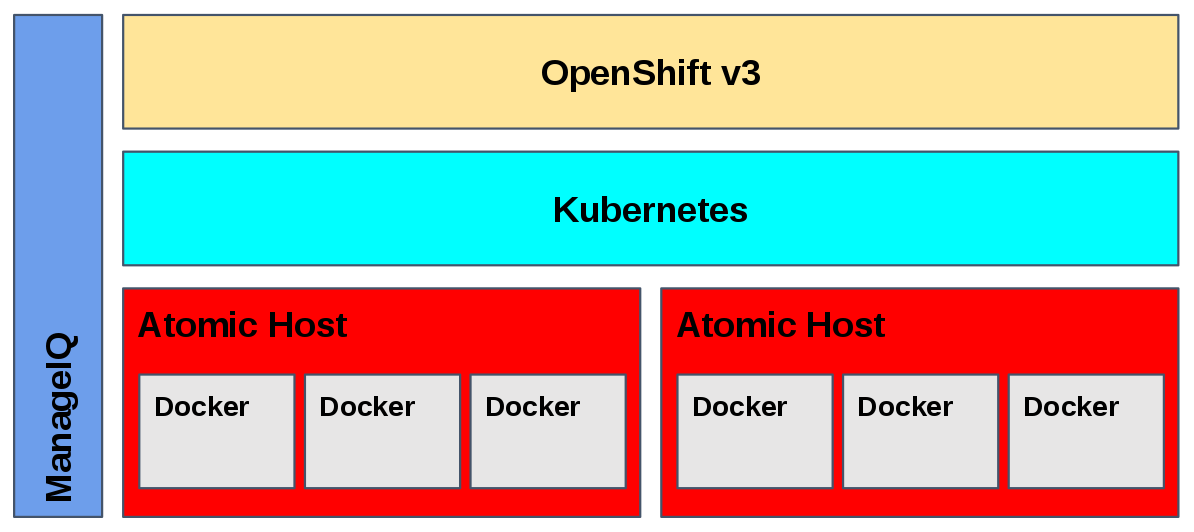
With our collaboration in the Docker and Kubernetes communities, as well as our rebuild of OpenShift and the introduction of Project Atomic, we are creating a highly efficient dev to ops pipeline that enterprises can use to deliver more value to their respective businesses. It also gives enterprises more choice:
- Want to use your orchestration framework? You can add that parameter to your Nulecule app definition and dependency graph.
- Want to use another container format? Add it to your Nulecule file.
- Want to package an application so that it can run on Atomic Host, Just Plain Docker, or OpenShift? Package it with Atomic App.
- Want an application management platform that utilizes all this cool stuff and doesn’t force you to manage every detail? OpenShift is perfect for that.
- Need to manage and automate your container infrastructure side-by-side with the rest of your infrastructure? ManageIQ is emerging as an ideal open source management platform for containers - in addition to your cloud and virtualization technologies.
As our container story evolves, we’re creating a set of technologies useful to every enterprise in the world, whether developer or operations-centric (or both). The IT world is changing quickly, but we’re pulling it together in a way that works for you.
Where to Learn More
There are myriad ways to learn more about the tools mentioned above:
- projectatomic.io - All the Atomic stuff, in one place
- openshift.org - Learn about the technology that powers the next version of OpenShift.com and download OpenShift Origin
- manageiq.org - ManageIQ now includes container management, especially for Kubernetes as well as OpenShift users
We will also present talks at many upcoming events that you will want to take advantage of:
- ContainerCon - new conference from the Linux Foundation, co-located with LinuxCon North America. It will feature talks on Atomic as well as OpenShift.
- USENIX Container Management Summit - co-located with USENIX LISA
ManageIQ with vSphere – Deploy and Configure
Found a really great blog post, all about deploying ManageIQ within a VSphere environment written by Jason Gaudreau: ManageIQ was made open source last summer; since it is a free download, I decided to try it out in my lab environment. I have it ma...
ManageIQ Botvinnik is Here – Control All the Things
We're very happy to announce that ManageIQ Botvinnik is now generally available. This marks the first full release cycle for ManageIQ as an open source project. As mentioned in previous announcements, we name our releases alphabetically after chess world champions. For the "B" release, we selected Mikhail Botvinnik, a Soviet chess champion from the 1950's. The "C" release cycle is named after Jose Raul Capablanca, a Cuban world chess champion from 1921-1927.
For the impatient, here's what you need to know:
- View a recent webinar about the Botvinnik release
- See the changelog
- Download Botvinnik
- Read some docs about using it for the first time
- Talk about it on talk.manageiq.org
Cloud management is very quickly morphing into systems management, to the point where the difference between the two is increasingly indistinguishable. Everyone has a cloud, somewhere. Everyone has a virtualization platform. ManageIQ has had management capabilities for popular platforms of both for some time.
What's new in the Botvinnik release, which marks the beginning of ManageIQ's evolution from "Your gateway to the open cloud" to "Control all the things," brings several important new features, including:
- More and better integration with cloud orchestration frameworks, including CloudFormations and OpenStack Heat.
- Comprehensive support for OpenStack infrastructure management.
- Bare metal provisioning and other integrations with The Foreman.
- The beginning of container management and Kubernetes integration
One of the key differentiators for ManageIQ is that it all starts with a comprehensive asset inventory and the relationships between them. Orchestration, automation, and the policy engine are built on that inventory base. First, know what is there, and then decide how to automate it. Other cloud management tools start with provisioning but lack the features necessary for what is described as "day 2 management." ManageIQ was built from the ground up following design principles geared for day 2 management. It can do provisioning as well, but its holistic, comprehensive approach is what truly sets it apart.
Botvinnik has a host of new features, and these are just a sample:
OpenStack Infrastructure Management (Undercloud)
- Infrastructure Provider (undercloud) in 2015
- Inventory for Heat Stacks
- Connect Cloud provider to Infra provider
- Autoscale compute nodes via Automate
- Infrastructure Host Events & Event processing
- Handling of power states (paused, rebooting, waiting, etc.)
- Tenant filtering based on security groups, floating IPs, and networks.
Foreman Provider Integration
- Enabled Reporting / Tagging
- Exposed Foreman models as Automate service models
- Zone enablement
- Added tag processing during provisioning
- Added inventory collection of direct and inherited host/host-group settings
- Organization and location inventory
Amazon AWS Support
- Inventory collection for AWS CloudFormation
- Parsing of parameters from orchestration templates
- Amazon Events via AWS Config service
- Enables event-based policies for AWS
- Added C4, D2, and G2 instance types.
- Virtualization type collected during EMS refresh for better filtering of available types during provisioning.
- Handling of power states
Orchestration Management
- Orchestration Stacks includes tagging
- Cloud Stacks: Summary and list views.
- Orchestration templates
- Create, edit, delete, tagging, ‘draft’ support
- Create Service Dialog from template contents
- Enabled Reporting / Tagging
- Improved rollback error message in UI
- Collect Stack Resource name and status reason message
Other Changes
- REST API: now at full parity with SOAP
- REST API: Added VM management capabilities
- Custom attributes
- Add lifecycle events
- Start, stop, suspend, delete
- Automate: new retirement workflow
- Fleecing: now supports qcow3, VSAN, OpenStack instances, systemd, XFS
- Kubernetes: EMS refresh scheduling, inventory collection
The comprehensive changelog is here.
All About Botvinnik Webinar – June 9
RSVP for the Botvinnik webinar! We're quickly coming up on the official release of ManageIQ Botvinnik. If you're curious about what are the most important additions to ManageIQ and how to use them, come to our online meetup next week where we'll walk ...
Additions to Planet ManageIQ
If you've been visiting Planet ManageIQ recently, you know we've made some additions: All Things Open - James Labocki's blog covering lots of ground on open source cloud infrastructure software and cloud management in general The Foreman Blog - W...
Botvinnik RC3 is here
The next Botvinnik release candidate, RC3, is now ready for download. Either use the site's download workflow or pick what you want from the list of available images. Report issues in this thread and link to the GitHub issue URL. If this one proves r...
Agenda for ManageIQ User Day at OpenStack Summit
As I mentioned in a previous blog post, we are having a day to ourselves on Wednesday, May 20 at the upcoming OpenStack Summit in beautiful Vancouver, British Columbia. We've been prepping and now have an agenda: 1:50 - 2:30 pm - Managing OpenSta...
ManageIQ Community Sprints – Now with Trello
If you've been participating in our sprint reports, you've no doubt found them to be an excellent way to stay apprised of feature progress in ManageIQ. I'm happy to announce that our community activities are now part of the 3-week sprints and included ...
